In
the 3rd session of Business Analytics we analysed the data of retail
stores.Some of the variables we analysed were price satisfaction,service
satisfaction,variety satisfaction,etc
With
the help of these variables we come to know that what the customer is sensitive
of,what are the factors that influence the satisfaction of the customer.
Using cross-tab to know the relationship
between two variables showing the that how much they are in relation to each other.
With the given group of data cross-tab helps in tabulating the results of one against the other.
They give a basic picture about the interrelation of two variables and help to
find out interactions between them. So today in the retail example we saw that
how customer satisfaction is affected by the different variables. This also helps us to know that what are the areas
that the store manager has to focus and improve upon.
For
example the comparison of the stores with service satisfaction.

After
this the chi-square test is done. Before the chi-square test a null hypothesis is created
showing that there is no relation between the variables compared and then if
the chi-square test result is more than .05 the null hypothesis is accepted
means that the variables are not in relation to each other and vice-versa.
Using
Data option (If function) to filter out unselected cases by giving
conditions. From the given set of data there are 39 people who after employee
contact, have negative service satisfaction level and are from store 2. This is
basically a filter tool to know the exact number and to detail upon them.
In
the 4th session we learned something known as Cluster Analysis.
Cluster
analysis or clustering is the task
of assigning a set of objects into groups (called clusters) so that the
objects in the same cluster are more similar (in some sense or another) to each
other than to those in other clusters.
There
are basically two ways of doing Cluster Analysis. They are:-
- Hierarchical:
- Done for <50 objects. Objects could be anything,i.e.;
people,place,etc
- K-Mean
:- Done for m >50 objects
Connectivity models:
Hierarchical clustering builds models based on distance connectivity.
Centroid models: K-Means
algorithm represents each cluster by a single mean vector.
Hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of
clusters. Strategies for hierarchical clustering generally fall into two types:
- Agglomerative Clustering : This is a "bottom up" approach: each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
- Divisive Clustering : This is a "top down" approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarchy.
Then we also studied about the Clustering Process. The process includes
three steps:-
- Selection of Process
- Distance Measurement. Probability, correlation, etc. Interpretation would be different as per different method used for measurement of distance
- Clustering Criteria
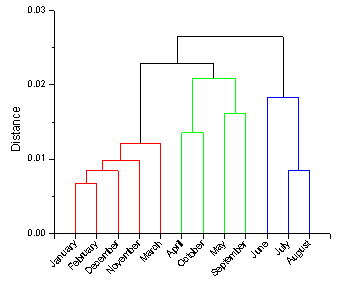
Dendrogram : - It is a tree diagram frequently used to illustrate the
arrangement of the clusters produced by hierarchical clustering.
Sunny Jaiswal
Roll No-14115
Roll No-14115
Operations Batch
Group-D
No comments:
Post a Comment