Cluster Analysis Using K-means
Finally, K-means cluster analysis is done after selecting the required cases by going to
Analyze>Classify>K-Means Clustering. Select the appropriate variables and the number of clusters required.
"K-means, was first published in 1955. In spite of the fact that K-means was proposed over 50 years ago and thousands of clustering algorithms have been published since then, K-means is still
widely used and is the most famous one."
Kautuk Popli (Group A)
Roll no:14023
SIBM-B
Cluster Analysis is a technique of grouping of obsevations owning same characteristic into one cluster.
K-means clustering is a method of cluster analysis which aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean.K-means is typically used with the Euclidean metric for computing the distance between points and cluster centers. It is different from hierarchical clustering; which is generally used when the number of observations is upto 50.
There is a matter of subjectivity involved while doing this kind of analysis. The first step before dividing the data into clusters, is to identify if there are any outliers which might prevent the formulation of appropriate clusters for analysis. For this, a Box Plot graph is appropriate that tries to eliminate these outliers (Extreme Values).
K-means clustering is a method of cluster analysis which aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean.K-means is typically used with the Euclidean metric for computing the distance between points and cluster centers. It is different from hierarchical clustering; which is generally used when the number of observations is upto 50.
There is a matter of subjectivity involved while doing this kind of analysis. The first step before dividing the data into clusters, is to identify if there are any outliers which might prevent the formulation of appropriate clusters for analysis. For this, a Box Plot graph is appropriate that tries to eliminate these outliers (Extreme Values).
Drawing of a Box Plot is an easy step using SPSS software.
Go to Graphs>Legacy Dialogs>Boxplot.
After this, choose the summary for category or continuous variable; and hence then click Define.
After choosing the variable/s, click ok

Thus, this graph shows the values which are centered around the median and the values which are the extremes/outliers. Here, the decision has to be made on which values to be skipped off from our analysis.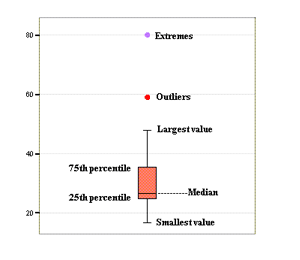
Finally, K-means cluster analysis is done after selecting the required cases by going to
Analyze>Classify>K-Means Clustering. Select the appropriate variables and the number of clusters required.
"K-means, was first published in 1955. In spite of the fact that K-means was proposed over 50 years ago and thousands of clustering algorithms have been published since then, K-means is still
widely used and is the most famous one."
Kautuk Popli (Group A)
Roll no:14023
SIBM-B
No comments:
Post a Comment